blog
更新日 : 2026/07/01
ノートPCにオープンミュトスを入れてみた2
前回の記事はこちら
アンソロピック(Anthropic)のクロード・ミュトス(Claude Mythos)が流行ってるっぽいので、使ってみようと思ったら。。。
一般公開が延期されているとのことで、使えないようです。(2026年5月現在)
指をくわえて待っているだけではさみしいので、オープン・ミュトス(Open Mutos)をノートパソコンに入れてみました。ちゃんと動くか確認してみます。
よくやる株価の推移から次の株価を予測するコードを書いてみます。
ステップ1:コードを書いて実行
1. 以下のコードを書きます。ここでは、2ndTest.ph というファイル名で保存しました。
import torch
import numpy as np
from open_mythos.main import OpenMythos, MythosConfig
# ==========================================
# 1. AIの準備 (軽量版)
# ==========================================
cfg = MythosConfig(
vocab_size=1000, dim=128, n_heads=4, max_seq_len=128,
max_loop_iters=2, prelude_layers=1, coda_layers=1,
n_experts=4, n_shared_experts=1, n_experts_per_tok=2,
expert_dim=32, lora_rank=8, attn_type="gqa", n_kv_heads=2
)
model = OpenMythos(cfg)
# ==========================================
# 2. ユーザーからの入力データ(配列)
# ==========================================
# [証券コード, 日付(YYYYMMDD), Open, High, Low, Close] の時系列データ
# 例として、トヨタ自動車(7203)の直近3日分のダミーデータ
input_array = [
[7203, 20260529, 3000, 3050, 2980, 3020],
[7203, 20260530, 3020, 3100, 3010, 3080],
[7203, 20260531, 3080, 3120, 3050, 3090]
]
target_code = input_array[0][0] # 今回予測する証券コード (7203)
print(f"入力データ: {len(input_array)}日分の配列を読み込みました。")
# ==========================================
# 3. データの翻訳(実数 → AI用トークンID)
# ==========================================
# AIが扱えるように、すべての数値を 0〜999 の範囲に圧縮(正規化)します
numpy_data = np.array(input_array)
# データ全体の最小値と最大値を取得(後で元に戻すために記憶しておく)
min_val = np.min(numpy_data)
max_val = np.max(numpy_data)
# 0〜999の整数に変換する関数
def encode_to_ai_token(value, min_v, max_v):
# 0.0〜1.0の割合に変換してから、999を掛けて整数にする
ratio = (value - min_v) / (max_v - min_v + 1e-9) # ゼロ除算防止
return int(ratio * 999)
# 入力配列をAI用の1次元トークン配列に変換
ai_input_tokens = []
for row in input_array:
for val in row:
token_id = encode_to_ai_token(val, min_val, max_val)
ai_input_tokens.append(token_id)
# PyTorchのテンソル(1行 × データ数の形)に変換
input_tensor = torch.tensor([ai_input_tokens], dtype=torch.long)
# ==========================================
# 4. OpenMythosによる推論(ループ思考)
# ==========================================
print("AIがループ思考で翌日の終値を予測中...")
# AIにデータを渡し、2回ループして深く考えさせる
output = model(input_tensor, n_loops=2)
# ==========================================
# 5. 結果の取り出しと翻訳(AI用トークンID → 実数)
# ==========================================
# AIが出した「次に来る確率が一番高いトークン」を取得
# output[0, -1, :] は一番最後のデータに対する予測確率リスト
predicted_token_id = torch.argmax(output[0, -1, :]).item()
# 0〜999の整数を、元の株価のスケール(実数)に復元する関数
def decode_to_real_value(token_id, min_v, max_v):
ratio = token_id / 999.0
return min_v + (ratio * (max_v - min_v))
# 予測されたトークンIDを実際の株価に戻す
predicted_price = decode_to_real_value(predicted_token_id, min_val, max_val)
# ==========================================
# 6. 最終的な出力データ(配列)の作成
# ==========================================
# [証券コード, 予想株価] の配列にする
output_array = [target_code, round(predicted_price, 1)]
print("--------------------------------")
print(f"【出力結果の配列】: {output_array}")
print("--------------------------------")2. さっそく実行します。
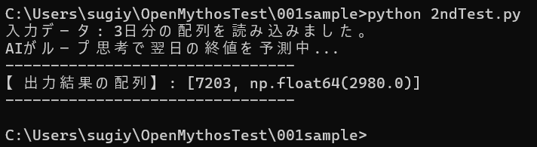
ちゃんと動いているようです。
ステップ2:コンフィグ(MythosConfig)の解説
コードの先頭にコンフィグ部分があります。ここを書き換えることで計算量を変えることができます。AIを巨大にして賢くしたり、逆に限界まで軽くして今回のようにノートパソコンでも動かせるようにできます。
専門用語が多いですが、それぞれの役割を「AIの脳の働き」に例えて、いくつかのグループに分けて順番に解説します。
1. AIの「基本スペック」を決める要素
・vocab_size=1000(語彙サイズ)
AIが知っている「単語(トークン)の種類」の数です。今回は超小型設定なので1000語しか知らない辞書を持たせていますが、本物のGPT-4やClaudeなどはここが数万〜10万以上になります。
・dim=128(次元数)
AIの「思考のパイプの太さ」や「情報処理の容量」です。数字が大きいほど複雑な意味合い(皮肉やニュアンスなど)を理解できますが、その分パソコンのメモリを大量に消費します。
・max_seq_len=64(最大シーケンス長)
AIが「一度に読み込める、または書き出せる最大の文字数(トークン数)」です。この設定だと、一度に64トークン分の短い文章しか処理できません。
2. オープンミュトスの特徴「ループ思考」の要素
・max_loop_iters=2(最大ループ回数)
オープンミュトスの心臓部です。 思考を何回グルグルと反復させるかの最大値です。2なら「最大2回まで深く考え直していいよ」という指示になります。
・prelude_layers=1(プレリュード層の数)
ループ思考に入る前の「準備運動(前処理)」をする層の数です。入力された言葉を、AIが考えやすい形に整理します。
・coda_layers=1(コーダ層の数)
ループ思考が終わった後の「まとめ(後処理)」をする層の数です。反復して考えた結果を、最終的な答えとして出力するために整えます。
3. AIの「専門家チーム(MoE)」を組織する要素
最新のAIは、すべての問題を脳の全体で考えるのではなく、内部にいる「専門家」に割り振って効率よく計算します(MoE:Mixture of Expertsと呼ばれます)。
・n_experts=4(専門家の総数)
AIの中にいる専門家の数です。「論理担当」「文法担当」のように、4つの専門機能を用意しています。
・n_shared_experts=1(共有専門家の数)
常に全員のサポートに回る「ゼネラリスト(一般的な知識を持つ専門家)」の数です。
・n_experts_per_tok=2(1つの言葉に対する担当者数)
入ってきた1つの単語に対して、「今回はこの2人の専門家が担当して!」と割り当てる数です。全専門家を動かさないことで、計算を軽くしています。
・expert_dim=32(専門家の次元数)
各専門家の「脳の容量」です。全体の dim=128 を分割して、専門家ごとに小さく割り当てています。
4. 読み取りの「視点」と「省エネ」の要素
・n_heads=4(アテンション・ヘッドの数)
文章を読むときの「視点の数」です。4なら、「主語と述語の関係」「感情」「時間軸」「重要なキーワード」という4つの別々の視点から、同時に文章を分析するイメージです。
・attn_type=”gqa”(アテンションのタイプ)
GQA(Grouped-Query Attention)という、「メモリを節約しながら賢く計算する省エネ技術」を使う設定です。GPUがないCPU環境でも動きやすくするために指定しています。
・n_kv_heads=2(キー・バリューのヘッド数)
上記のGQA(省エネ技術)で使う設定です。視点(ヘッド)が4つあるうち、記憶領域(KV)を2つにまとめて共有させることで、パソコンのメモリ消費を半分に抑えています。
5. その他の補助要素
・lora_rank=8(LoRAのランク)
AIの動きを微調整したり、効率よく学習させたりするための「LoRA(ローラ)」という仕組みの計算サイズです。8という小さな数字にして、計算を軽くしています。
まとめると:
この設定は、「知っている言葉は少なく(vocab_size=1000)、脳の容量も小さい(dim=128)けれど、4人の専門家チーム(n_experts=4)と省エネ技術(gqa)を駆使して、最大2回(max_loop_iters=2)反復して考えることができる、超軽量なテスト用AI」を組み立てている、ということになります。
ステップ3:データの考察
今回のサンプルコードでは、証券コードと日付と4本値をまとめて入力しました。
このデータの与え方はよろしくありません。
証券コードと時間、価格の概念が混ざってしまい、正しく推論できないためです。
もう少しかみ砕くとこうです。
1.数値のスケール(桁数)が混ざって価格の波が消える
先ほどのコードでは、データ全体を見て最小値と最大値を決めました。
しかし、日付は「20,260,531」といった巨大な数値であるのに対し、株価は「3,000」程度です。これを一緒に「0〜999」に圧縮すると、株価の数十円の上下(波)はAIにとって
「ほぼ誤差(変化なし)」として潰れてしまい、波形を認識できなくなります。
2.役割の区別がなく「ただの数字の列」になっている
配列を1列に並べ直して入力したため、AIから見ると
「証券コードの数字 → 日付の数字 → 始値の数字 → 高値の数字…」というルールが
事前にはわかりません。
人間なら「ここは日付だな」とわかりますが、AIはそれを膨大な学習ループの中で
自力で推測しなければならず、非常に非効率です。
今回のケースでは、次の営業日の株価を予測したかったため、日付は省いてよいデータです。
4本値は1日ずつのデータであるため、初値、高値、安値、終値の順を守って配列で渡せば問題なさそうです。
時系列予測においてデータの「前処理」と「入力構造の設計」は、AIモデル自体の性能よりも重要だと言われるほど奥深い分野だそうです。前処理と入力構造をしっかり設計して、結果の確からしさが向上するように頑張りましょう!