blog
更新日 : 2026/04/01
AIエージェントを使ったNDL調査の自動化 ②
前回までで要件が定まったので、今回からは設計や実装、と言っても指示出してよしなにしてもらう感じです。
なお、ここから動作環境は以下のようになります。
・ OS:Windows11
・ Claude Code:2.1.73
設計~テスト
要件が決まった際に要件定義と使用する各エージェントを作成してもらいました。エージェントは設計用・実装用・テスト用と実際の調査で動くものの4種類となります。これらを同一のディレクトリに移し、コマンドプロンプトからClaude Codeを立ち上げます。
Claude Codeの使い方は様々なサイトにて説明があるのでここでは割愛させてもらいます。
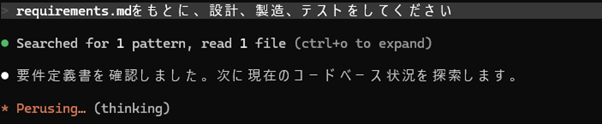
Claude Codeに「要件定義書をもとに設計・製造・テストをしてください」とPlanモードで指示をするときちんと作業計画を立ててそれを基にタスクを行なってもらえます。かなり便利。
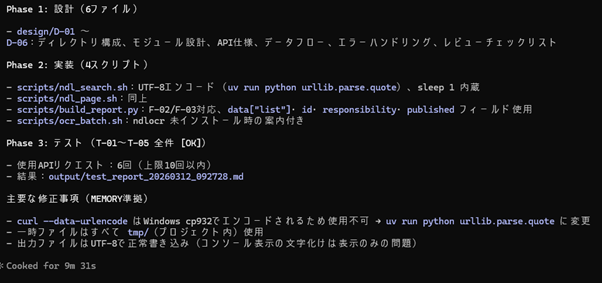
10分かからない程度でテストまで終了。あっという間にできてしまいます。
できてしまうのですが、生成されたソースコードを確認するとエラーメッセージ等がべた書きになっていました。べた書きにしてほしくないものは別に書くなど、Claude.mdに実装方針を明記しておくことが大事なようです。
実際に動かしてみる
テストまで終わったのでお試しで動かしてみましょう。
今回のテーマは「丸善」。理由は簡単。明治期からある企業なのでNDLに資料がかなりありそう+ある程度の資料や概略なら自分も見当がつくので提示された答えを丸呑みしないで済むからです。それと横浜発祥の企業なので……

上記テーマでレポート生成をしてもらうよう指示を出し、結構あっという間に作ってくれました。
キーワードとしてしっかり丸屋善七が入っているのがよい。

洋書販売など入っているのでまあOKだと思います。

ざっくり結果を見てみたのですが、「旧称・丸善商會」は違うんじゃないかなぁ。丸屋商社だったはず。おそらく文献として提示してきた『商人立志伝』の「丸善商會」という記述をそのまま持ってきたのではと判断。細かい事実関係は要確認ですが、ざっくりそれっぽいものは作られていました。創業者名は合っています。

また、文献のみ提示するようにも指示を出してみました。
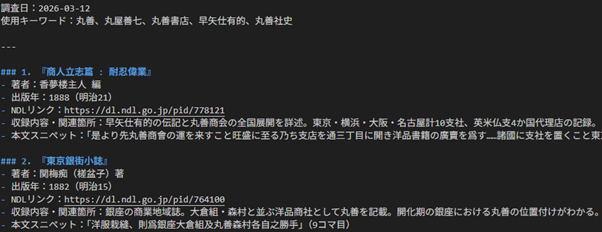
使用キーワードについては特に問題ないです。文献を出してもらう点数を調整できるようにしてもらうのもいいかもしれないですね。
今回はNDLOCR-Liteを使った前処理をせずにやってみましたが、前処理をしたらもう少し精度上がるのでは?と思っていたりします。

実装時にこんなこと言ってたのに正しくデータ取れるようになっていました。ただ正直、「間違えているなら正しいエンドポイント記述にすること」のような内容は指示した方がいい気がします。指示していない内容はやらなかったりやったり曖昧なので……
今後の課題など
「大体あってる」ようなレポートを出してくれるようになったので、細かい事実関係などが気になってきました。こちらをどう詰めていくかというのも気になるのですが、似たようなジャンルを調べている際によく参照する文献があったり、「この文献にはこう書いてあるから……」ということが頭の中にあったりとなんとなくの勘所というかショートカットができることがあります。コンテキストメニューが消えたらこれまで調べた内容は消えてしまうはずなので、既に調べた内容を記憶しておく仕組みを作っておき、似たジャンルや内容の検索時に参照して精度を上げたりできればと思っていたりします。これはできれば今後やってみたいです。
上記以外に調査精度の改善について壁打ち相手に聞いてみると、「NDC(日本十進分類)でのフィルタリング」・「ナレッジグラフ」・「再帰的フィードバックを用いた調査手法の動的更新」など提示してもらいました。この中ではおそらくNDCでのフィルタリングが一番簡単な気がします。
NDC以外にもNDLC(国立国会図書館分類表)でのフィルタリングも気になるので、双方使ってみたいところです。NDLCだけという形では採用しないです。「国会図書館にはない本はない」と思っている方が結構いるようですが、探してみると意外とないです。東京23区以外の1950年代の住宅地図は地図室に収蔵されてないですし。(リサーチ・ナビ「住宅地図」参照)
と、色々書きましたが次回以降は調査精度の改善となると思います。ただここから先は専門的な知識が必要となってくるので壁打ち相手のAIが言ってきたことを鵜呑みにしないで方針を決めたいので、図書館情報学やデジタル・ヒューマニティーズなどの文献をいくつか読み漁ってからにしたいと思います。
今回やった調査の自動化は資料があれば検索できるのですが「そもそもオープンな資料がない」という場合は調べることができないです。調査可能な範囲は「国立国会図書館デジタルコレクション」でインターネット公開をしている著作権保護期間満了となった図書及び古典籍のデジタル化資料」なので、ここの資料が増えていけば確認できる点数が増えていきます。それでもオープンデータの調査の効率はある程度改善できそうな気がします。